Hapax legomena, woorden die maar eenmaal voorkomen in een tekst, worden onder andere gebruikt om auteurschap van een tekst te bepalen. Hoewel daar tegenwoordig andere, robuustere manieren voor bestaan, worden hapax legomena nog wel gebruikt in corpusonderzoek en daarbuiten – zo laat onderzoek van Hernández-Domínguez et al. (2018) zien dat de frequentie van hapax en dis legomena (woorden die respectievelijk een- en tweemaal voorkomen) gecorreleerd is aan cognitieve stoornis (zie ook Alegria & Radanovic, 2019).
Voor vertalingen van bijbelteksten en (andere) klassieke teksten vormen hapax legomena een moeilijkheid; de betekenis van de woorden is moeilijk te achterhalen, omdat dat meestal gebeurt door verschillende gebruiken/contexten met elkaar te vergelijken en bij hapaxen kan dat niet.
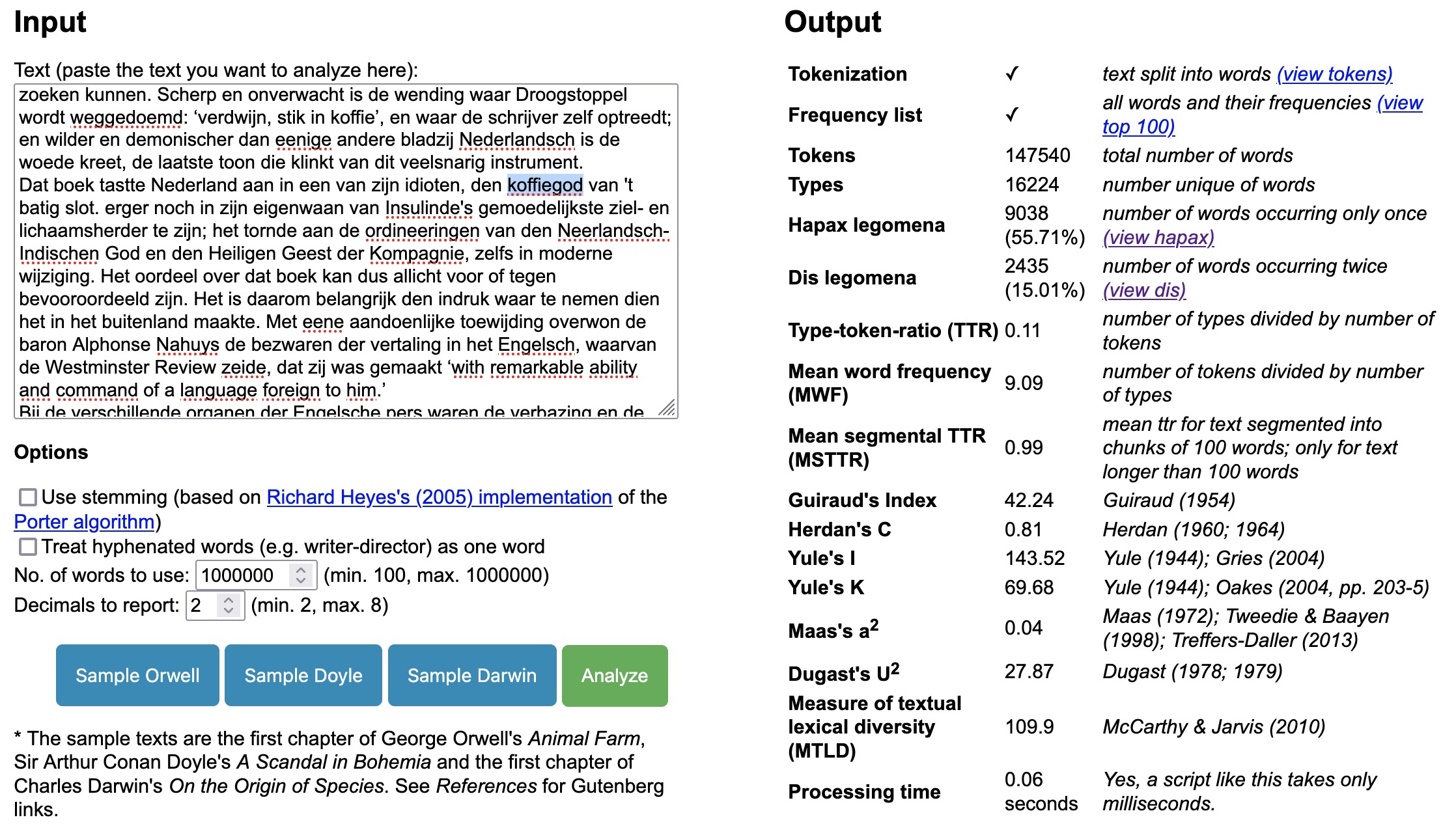
Hoe dan ook, op https://www.reuneker.nl/ld kun je zelf de hapaxen uit een tekst halen. Wist je bijvoorbeeld dat het woord koffiegod precies een keer voorkomt in de Max Havelaar, namelijk in de onderstaande passage?
Scherp en onverwacht is de wending waar Droogstoppel wordt weggedoemd: verdwijn, stik in koffie, en waar de schrijver zelf optreedt; en wilder en demonischer dan eenige andere bladzij Nederlandsch is de woede kreet, de laatste toon die klinkt van dit veelsnarig instrument. Dat boek tastte Nederland aan in een van zijn idioten, den koffiegod van 't batig slot.
Hapax Legomena in de Max Havelaar
 Online t-toets-calculator
Online t-toets-calculator

