I keep finding myself fiddling with treadmill speeds and the calibration thereof. I am fully aware though, that really exact speeds don't matter that much in running/training, but I just find it fascinating. I also kept finding myself calculating intermittent speeds between two calibrated speeds in a very inefficient way. Now I've come to value inefficiency a bit more in the last couple of years (or, better said, I've come to devalue efficiency...), but this task was just to repetitious and, to be frank, boring. That's why I've added an interpolation function to the treadmill calculator.
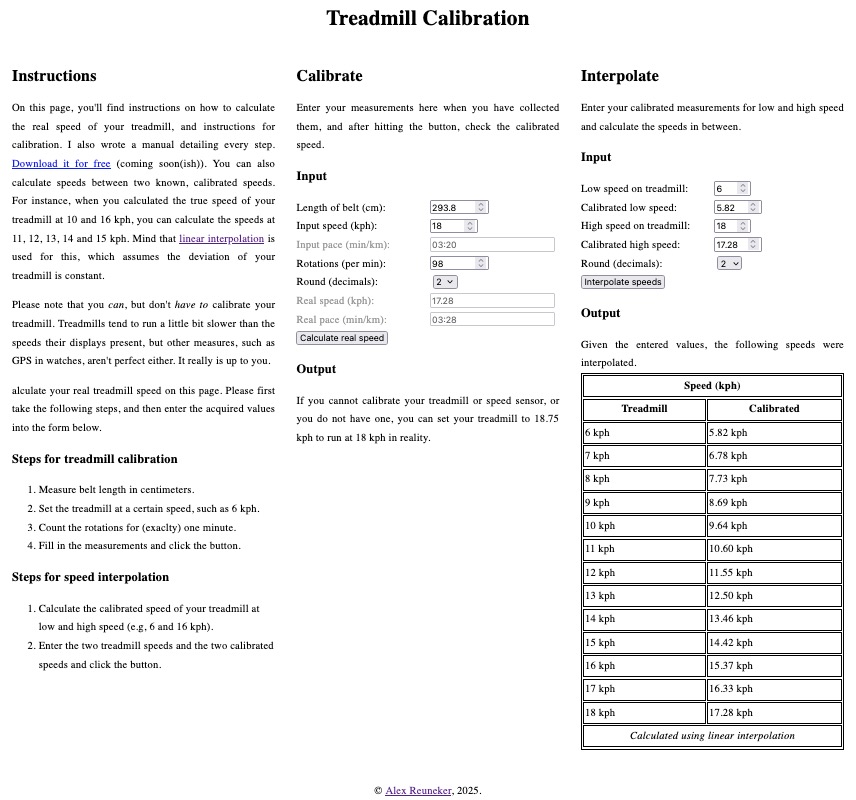
Interpolation for calibrated treadmill speeds
With this new function, you can enter two previously calibrated speeds and calculate the 'correct' speeds in between. For instance, when you calculated the true speed of your treadmill at 10 and 16 kph, you can calculate the speeds at 11, 12, 13, 14 and 15 kph. Keep in mind that linear interpolation is used for this, which assumes the deviation of your treadmill is constant. This probably is not an entirely correct assumption, but that's the margins of the margins, I'd say. Anyway, if you find it useful, let me know!
Link: https://www.reuneker.nl/treadmill


